テキストマイニングとは
アンケート調査から得た自由記述回答やSNSへの投稿データなど、さまざまなテキストデータを解析(テキストマイニング)し、自社や商品に対し、消費者が抱くイメージや満足度などを抽出します。
テキストマイニングの特徴
- 膨大な自由回答データ(定性情報)を、ソフトウェアを用いて処理することで、迅速に定量化、かつビジュアル化することを可能にし、時間とコストの削減を実現いたしました。
- 単純に定量化するだけでなく、回答データの分類や、単語間のつながりも分析可能という点で、自由回答データの「傾向」や「構造」を発見するのに最適です。
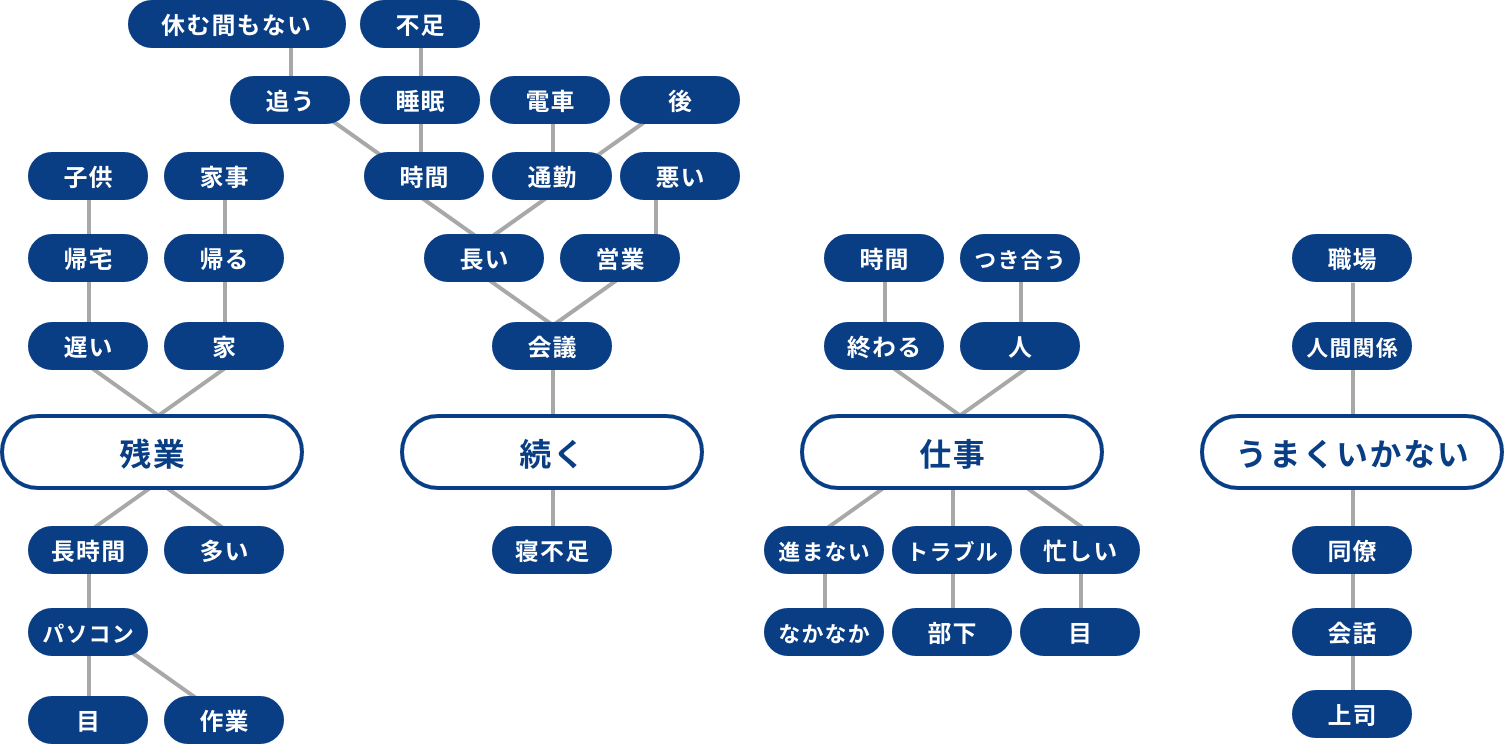
テキストマイニングの活用方法例
ブランドイメージ構造、キーワードの抽出
あるブランドに対する自由回答データを「単語」に分解し、「単語間の繋がり」を整理することで、重要なイメージキーワードを発見するとともに、イメージ構造を可視化することが可能です。
商品・サービス利用価値の源泉の発見
ある商品・サービスを使っている時の気分など自由回答データの分析を通じて、生活者が考える商品・サービスのベネフィットの傾向を発見することが可能です。
調査の流れとスケジュールグループ/ディテールドインタビューの中で分析を実施。
01
自由回答を「単語」に分類
自由回答を「単語」単位に分解します。
02
単語同士の「つながり」を
検証
単語間の「関連性」の強さを算出します。
03
マップとしてビジュアル化
Step1,2の結果を元に、主な「単語」と「繋がり」を連鎖的にビジュアル化します。
RESEARCH SERVICEサービスを課題から探す